퇴근길에 만난 저녁 노을.




참 오랜만에 보는 노을이다.
퇴근길에 만난 저녁 노을.
참 오랜만에 보는 노을이다.
오늘은 영은양 음력 생일이다. 이미 양력 생일상은 다 차려 먹었지만, 장모님이 올해는 윤년이라 음력생일도 챙겨야 한다고 하셔서 저녁에 처가집에 가서 저녁을 먹을 예정이었으나, 내일 어머니가 올라오시는 관계로 취소 됐다. 그래서 생일상 대신 나들이를 다녀오기로 하고 김포공항 아울렛으로 영화를 보러 갔으나, 표가 없어서 그냥 거기서 에어컨 바람 쐬다가, 집으로 그냥 가기 아쉬워서 무작정 임진각으로 가보았다.
그런데 오우, 집에서 한시간 남짓한 거리에 이런 곳이 있었다니…

주차장에서 내리면 젤 먼저 눈에 띄는 저 바람개비들~~~ 이런 곳을 예상치 못하고 50mm 단렌즈 딸랑 하나 들고 갔더니 바람개비가 팽글팽글 도는 역동적인 모습을 잡기엔 너무 강한 햇살!!! ND 필터를 못 챙겨간게 무척 아쉽다.

하지만 날이 너무 덥고 햇빛이 강해서 바로 그늘에 자리 잡고 휴식에 들어가시는 마나님. 저 은박 돗자리가 땅 바닥의 돌을 전혀 커버해주지 못해서 집에 오는 길에 마트 들러서 폭신한 등산용 매트리스를 재 구매했다.

하지만 목이 마르구나. 연못 위 카페에 들러서 음료수 한잔씩 해 주셨다. 한글로 된 카페 이름이 낯설다. 우째 이런 일이… 스타**, 커피** 따위에 “안녕”이 밀리다니… 너무 외국 이름에 물들어 있나 보다.

“철마는 달리고 싶다” 라는 문구와 함께 많이 등장했던 저 기관차. 곳곳에 총알 구멍이 숭숭 뚫려 있다. 힘차게 달리는 은하철도 999 기억 때문인지, 아무리 오래된 증기 기관차라도 언제라도 움직일것만 같았는데 상처투성이로 녹슬어 있는 이 기관차를 보니 참 안쓰럽다.

때 이른 잠자리. 아직 날이 더운데 일찍도 나왔구나.

길은 여기서 끝났다. 건너편엔 도라산역으로 가는 전철이 지나는 철길인데 막혀 있더라. 태극기 휘날리며 걸음을 돌리는 유여사.

돌아 가기전 포즈 한번 취해 주신다. 저 뒤로 쭉 이어진 나무 난간이 참 예뻐서 자세하게 잡았더니 사람들이 덩달아 배경에 자꾸 나와서 아쉽지만 그냥 배경은 날렸다.

마지막으로 들른 전망대엔 망원경을 무료로 이용할 수 있었다. 열심히 북한군 관찰중이신 마나님. 하지만 북한군은 뵈지 않더라. 손으로 렌즈를 싸서 손후드를 씌웠음에도 불구하고, 플레어 작열 해주신다. SMC 코팅도 한여름 태양과의 정면 승부는 힘들구나. 차라리 싸구려 필터를 빼고 찍을걸 그랬다.
임진각. 다음에 또 만나요.
토요일 저녁마다 찾아가는 처갓집.
우리집을 나서서, 처갓집으로 출발.

오늘은 무슨 맛난 것을 해 주실라나. ㅋ

으쌰, 으쌰, 힘차게 걸어가는 영은양!
며칠전 미디어법 관련 백분토론을 보면서 딴나라가 아주 발악을 하는 구나 했는데 이 정도 일 줄은 몰랐다.
http://www.pressian.com/article/article.asp?Section=02&article_num=60090629101256
양심을 팔아서 보고서를 쓴 사람들… 괴롭기는 하냐.
2009/02/01 – [주저리주저리] – 윗 사람의 마음가짐
저번엔, 금융연구원장의 퇴임사를 보면서 정권은 국책 연구소에도 외압을 행사 한다는 사실을 배웠다. 그리고 이번엔, 그 외압에 굴복했을 때 그 결과가 이런 식으로 나온다는 것을 또 배운다. 이 정권이 딱 하나 잘 하는게 있다면 국민들에게 정부가 할 수 있는 수만가지 부도덕한 짓거리들을 어떻게 하는지 몸소 실천해서 보여준다는 것이다. 참 좋은 공부 시키는구나. 두고 두고 잊지 않겠다.
* developer
HBase : Apache?
Hive : Facebook
CloudBase : Business.com
* Hadoop
HBase – Hadoop 각 버전에 대응
Hive – Hadoop 0.17
CloudBase – Hadoop 0.18+
* SQL 지원
HBase : 간단한 db 연산, 기존 프로그램과 연동 어려움.
Hive : Hive QL (SQL 과 조금 다름), JDBC 드라이버 제공, 기존 프로그램과 연동 어려움.
hive> CREATE TABLE pokes (foo INT, bar STRING);
Creates a table called pokes with two columns, the first being an integer and the other a string
hive> CREATE TABLE invites (foo INT, bar STRING) PARTITIONED BY (ds STRING);
Creates a table called invites with two columns and a partition column called ds. The partition column is a virtual column. It is not part of the data itself but is derived from the partition that a particular dataset is loaded into.
By default, tables are assumed to be of text input format and the delimiters are assumed to be ^A(ctrl-a).
hive> SHOW TABLES;
lists all the tables
hive> SHOW TABLES '.*s';
lists all the table that end with ‘s’. The pattern matching follows Java regular expressions. Check out this link for documentation ![]() http://java.sun.com/javase/6/docs/api/java/util/regex/Pattern.html
http://java.sun.com/javase/6/docs/api/java/util/regex/Pattern.html
hive> DESCRIBE invites;
shows the list of columns
As for altering tables, table names can be changed and additional columns can be dropped:
hive> ALTER TABLE pokes ADD COLUMNS (new_col INT);
hive> ALTER TABLE invites ADD COLUMNS (new_col2 INT COMMENT 'a comment');
hive> ALTER TABLE events RENAME TO 3koobecaf;
Dropping tables:
hive> DROP TABLE pokes;
Loading data from flat files into Hive:
hive> LOAD DATA LOCAL INPATH './examples/files/kv1.txt' OVERWRITE INTO TABLE pokes;
Loads a file that contains two columns separated by ctrl-a into pokes table. ‘local’ signifies that the input file is on the local file system. If ‘local’ is omitted then it looks for the file in HDFS.
The keyword ‘overwrite’ signifies that existing data in the table is deleted. If the ‘overwrite’ keyword is omitted, data files are appended to existing data sets.
NOTES:
NO verification of data against the schema is performed by the load command.
If the file is in hdfs, it is moved into the Hive-controlled file system namespace. The root of the Hive directory is specified by the option ‘hive.metastore.warehouse.dir’ in hive-default.xml. We advise users to create this directory before trying to create tables via Hive.
hive> LOAD DATA LOCAL INPATH './examples/files/kv2.txt' OVERWRITE INTO TABLE invites PARTITION (ds='2008-08-15');
hive> LOAD DATA LOCAL INPATH './examples/files/kv3.txt' OVERWRITE INTO TABLE invites PARTITION (ds='2008-08-08');
The two LOAD statements above load data into two different partitions of the table invites. Table invites must be created as partitioned by the key ds for this to succeed.
hive> SELECT a.foo FROM invites a WHERE a.ds='<DATE>';
selects column ‘foo’ from all rows of partition <DATE> of invites table. The results are not stored anywhere, but are displayed on the console.
Note that in all the examples that follow, INSERT (into a hive table, local directory or HDFS directory) is optional.
hive> INSERT OVERWRITE DIRECTORY '/tmp/hdfs_out' SELECT a.* FROM invites a WHERE a.ds='<DATE>';
selects all rows from partition <DATE> OF invites table into an HDFS directory. The result data is in files (depending on the number of mappers) in that directory. NOTE: partition columns if any are selected by the use of *. They can also be specified in the projection clauses.
Partitioned tables must always have a partition selected in the WHERE clause of the statement.
hive> INSERT OVERWRITE LOCAL DIRECTORY '/tmp/local_out' SELECT a.* FROM pokes a;
Selects all rows from pokes table into a local directory
hive> INSERT OVERWRITE TABLE events SELECT a.* FROM profiles a;
hive> INSERT OVERWRITE TABLE events SELECT a.* FROM profiles a WHERE a.key < 100;
hive> INSERT OVERWRITE LOCAL DIRECTORY '/tmp/reg_3' SELECT a.* FROM events a;
hive> INSERT OVERWRITE DIRECTORY '/tmp/reg_4' select a.invites, a.pokes FROM profiles a;
hive> INSERT OVERWRITE DIRECTORY '/tmp/reg_5' SELECT COUNT(1) FROM invites a WHERE a.ds='<DATE>';
hive> INSERT OVERWRITE DIRECTORY '/tmp/reg_5' SELECT a.foo, a.bar FROM invites a;
hive> INSERT OVERWRITE LOCAL DIRECTORY '/tmp/sum' SELECT SUM(a.pc) FROM pc1 a;
Sum of a column. avg, min, max can also be used
CloudBase : ANSI SQL, JDBC 드라이버 제공, 기존 프로그램과 연동 어려움.
CREATE TABLE table1 ( c1 VARCHAR, c2 INT) COLUMN SEP ‘|’
This creates an empty table- table1 with 2 columns- c1, c2 having VARCHAR and INT datatypes respectively. The column sep (‘|’) indicates the files that will be added into this table will have ‘|’ as the delimiter.
CREATE TABLE table1 ( c1 VARCHAR, c2 INT) COLUMN SEP ‘|’ HDFS PATH ‘logs/weblogs’
This creates a table- table1 and attach this name with the path- ‘logs/weblogs’ on Hadoop File System. If this path exists and has files then those files will constigute the table data. The column sep indicates that the ‘|’ char is used as delimter char in these files. If the path does not exist, it will be created. In that case the table won’t have any data, i.e. select query on this table will return 0 rows.
CREATE TABLE table1 ( c1 VARCHAR, c2 FLOAT) COLUMN SEP ‘t’ IMPORT DATA FROM ‘/home/logs/weblogs’
This creates table- table1 and copy data from the given local path. TAB (‘t’) is used as a delimter char. The data is loaded on Hadoop File Sysem in the directory- cloudbase/data/<tablename>
CREATE XML TABLE <tablename>
( <column name> <data type> ‘XJPath’ [, <column name> <data type> ‘XJPath’ , …] )
START WITH ‘start_tag’ END WITH ‘end_tag’
[ HDFS PATH <hdfs path> ]
[ IMPORT DATA FROM <local path> ]
[ COMMENT <string> ]
If the root tag has no attribute, one can simply use the ROOT TAG clause. The START TAG along with END TAG is preferred only when xml root tag has attributes.
The input log file/data can be in any format as long as XML records can be identified by start and end tags. For example,
some text
<book> xml data record 1</book>
some text
<book> xml data record 1</book>
Drop table syntax-
DROP TABLE tablename [ DO NOT PURGE DATA ]
INSERT statement is used to insert data-
• Into an already existent CloudBase table from local files.
• Into an already existent CloudBase table from another CloudBase table.
• Into a RDBMS Table (via a database link).
Inserting data into CloudBase table from local files
INSERT INTO <tablename> IMPORT DATA FROM ‘local/path’
The local files should have the same structure as defined in table’s meta data, i.e. local files should have the same delimiter, same number of fields as defined in table’s meta data.
Inserting data into CloudBase table from an existent table
INSERT INTO <tablename>
[ ( column_name1, column_name2, …) ]
<query>
Examples:
INSERT INTO table2
SELECT c1, c2, c3 FROM table1
This will dump the output of query into table2
INSERT INTO table2
( col2, col1, col3 )
SELECT c1, c2, c3 FROM table1
This will dump the output of query into table2 in the specified column order.
If insufficient columns are specified,then INSERT statement will insert NULL values for the remaining columns.
Inserting data into an external (RDBMS) table
INSERT INTO <tablename>@database_link_name
[ ( column_name1, column_name2, …) ]
<query>
Examples:
INSERT INTO table2@sql_server_link
SELECT c1, c2, c3 FROM table1
This will dump the output of query into table2 in the RDBMS as specified by the database link- sql_server_link
If insufficient columns are specified,then INSERT statement will insert NULL values for the remaining columns.
Select statement syntax
The syntax of SELECT statement is as follows-
SELECT [ DISTINCT ] [ TOP <number> ]
column1 [ , colum2, column3, … ]
[ into_clause ]
FROM <from_list>
[ join_clause ]
[ where_clause ]
[ group_by_clause [ having_clause ] ]
[ order_by_clause ]
[ on error clause ]
Clauses present in ‘[ ]’ indicate that they are optional
FROM clause
One can use tables, views and/or sub queries in the from-clause. Aliases can be optionally set for table names and views. However, setting aliases for sub queries is mandatory.
Examples:
• SELECT * FROM test_table1
• SELECT * FROM ( SELECT c1, c2 FROM test_table1) AS T
• SELECT DISTINCT c1 FROM test_table1
JOIN clause
CloudBase supports inner and outer (left, right, full) joins via ANSI SQL’s explicit join syntax-
• SELECT * FROM test_table1 AS t1 INNER JOIN test_table2 AS t2 ON t1.c1 = t2.c1
Join Syntax-
• SELECT * FROM test_table1 AS t1 [ OUTER ] LEFT | RIGHT | FULL JOIN test_table2 AS t2 ON <join condition>
Sub queries can also be used instead of tables/views –
• SELECT * FROM test_table1 AS t1 INNER JOIN (SELECT * FROM test_table2) AS t2 ON t1.c1 = t2.c1
WHERE clause
Rows returned by queries can be filtered by using Where clause. At present CloudBase supports the following conditions in the Where Clause-
• Arithmetic condition- compare columns using arithmetic operators- <, >, =, <=, >=, !=, <> (either of !=, <> can be used for not equal to)
• Between condition- e.g. WHERE c1 BETWEEN 10 and 100. NOT can also be used with BETWEEN- WHERE c1 NOT BETWEEN 10 and 100
• IS NULL condition- e.g. WHERE c1 IS NULL. NOT can also be used- WHERE ci is NOT NULL
• Like condition- e.g. WHERE c1 LIKE ‘%abc%’. NOT can also be used- WHERE c1 NOT LIKE ‘%abc%’. To match on a single character use ‘?’. One can use regular expressions in LIKE clause. See below for details.
Boolean AND / OR can be used to tie conditions together, e.g-
• SELECT * FROM test_table1 WHERE c1 LIKE ‘z%’ AND c2 > 10
• SELECT * FROM test_table1 WHERE c2 > 40 OR c3 < 20
CloudBase supports SQL wild cards- ‘%’ and ‘?’ in LIKE conditions. For conditions that can not be expressed using these wild cards, one can use regular expressions. CloudBase supports regular expression similar to Java programming language. One can read about Java regular expressions here
Examples:
• SELECT c6 FROM test_table3 where c6 like ‘b[ea]ta’
matches ‘beta’, ‘bata’
• SELECT * FROM test_table3 WHERE c like ‘(l|L)earning’
matches ‘learning’, ‘Learning’
• SELECT c FROM test_table WHERE c LIKE ‘(z|Z)o{3}+m’
matches all values of column c that begins with z or Z followed by EXACTLY 3 o’s and then m
• SELECT c FROM test_table WHERE c LIKE ‘(z|Z)o{3,}+m’
matches all values of column c that begins with z or Z followed by AT LEAST 3 o’s and then m
• SELECT c FROM test_table WHERE c LIKE ‘(z|Z)o{3,}+m’
matches all values of column c that begins with z or Z followed by AT LEAST 3 o’s and then m
• SELECT c FROM test_table WHERE c LIKE ‘(z|Z)o{3,6}+m’
matches all values of column c that begins with z or Z followed by AT LEAST 3 but NOT MORE THAN 6 o’s and then m
To escape regular expression construct, use ‘’. For example-
• SELECT c FROM test_table WHERE c LIKE ‘[abc]’
matches literal string- ‘[abc]’
Aggregate functions and GROUP BY clause
CloudBase supports aggregate functions and group by clause. The aggregate functions supported by CloudBase are- SUM, COUNT, MAX, MIN, and AVG. One can use GROUP BY cluase in conjunction with the aggregate functions to group the result-set by one or more columns. In Group by clause, one can use column names, alias or index of column present in the select clause. e.g.-
Examples:
• SELECT c4, COUNT(*) FROM test_table1 GROUP BY c4
• SELECT c1, SUM(c2) FROM test_table1 GROUP BY c1
• SELECT c1 as a, SUM(c2) FROM test_table1 GROUP BY a
• SELECT c1, c4, SUM(c2) FROM test_table1 GROUP BY 1,2
• SELECT COUNT(c1),MAX(c2),MIN(c3), c4 FROM test_table1 GROUP BY c4
DISTINCT in Aggregate functions
• SELECT COUNT( DISTINCT c1), MAX(c2) FROM test_table1
• SELECT COUNT( DISTINCT c1), MAX(c2), MIN(c3), COUNT(DISTINCT c4) FROM test_table1
DISTINCT in Aggregate functions with GROUP BY
• SELECT COUNT( DISTINCT c1), COUNT( DISTINCT c2), COUNT( DISTINCT c3), COUNT( DISTINCT c4), MAX(c2), MIN(c2), MAX(c3), MIN(c3), c4 FROM test_table1 GROUP BY c4
HAVING clause with GROUP BY
• SELECT COUNT(c1) cnt_c1, COUNT( DISTINCT c2) cnt_d_c1, SUM(c2) sum_c2, SUM(c3) sum_c3, c4 FROM test_table1 GROUP BY c4 HAVING cnt_d_c1 > 2 AND sum_c3 > 100
• SELECT COUNT(c1) cnt_c1, MAX(c4) max_c4, MIN(c4) min_c4, MAX(c5) max_c5, MIN(c5) min_c5, SUM(c4) sum_c4, SUM(c5) sum_c5, COUNT(DISTINCT c1), SUM(DISTINCT c4), c6 FROM test_table3 GROUP BY c6 HAVING c6 LIKE ‘%p%’
ORDER BY clause
ORDER BY clause can be used to sort result set on one or more columns. One can sort in ascending order (default behavior) or in descending order. Just like Group By clause, one can use column name, alias or column index in the ORDER BY clause.
Examples:
• SELECT c1, c2, c3, c4 FROM test_table1 ORDER BY c1
• SELECT c1 as a, c2 as b, c3 as c, c4 as d FROM test_table1 ORDER BY a, b
• SELECT c1, c2, c3, c4 FROM test_table1 ORDER BY 3
• SELECT * FROM test_table1 ORDER BY c4 DESC, c2
insert 동작이 Hive, CloudBase 모두 로컬 파일 시스템이나 HDFS 상의 파일, 혹은 DB상의 테이블, 또는 외부 프로그램의 출력 결과를 stream 으로 batch 업로드 하게 되어 있음. 프로그램 안에서 개별 레코드 데이터를 넣는 방법이 없음. 대량의 텍스트 데이터를 db에 업로드 후, 원하는 db 연산을 한 결과를 받아보는 식의 batch 작업 형태임. 프로그래밍을 위한 db 라기 보다, 대량 텍스트 데이터를 DB 연산 형식을 차용해 mapreduce 의 복잡한 프로그래밍을 하지 않고 SQL 질의만으로 원하는 결과를 얻는 식 임. SQL문을 적절히 처리하여 내부적으로는 hdfs 상에서 mapreduce 작업으로 결과를 가져옴. 개별 레코드에 대한 insert 가능한지는 API 문서나, 사용 샘플 코드를 봐야 하겠지만, 파악했던 Document 페이지들 상에서의 샘플 코드에서도 DATA 혹은 XML 파일을 배치 업로드 하는 것만 있음. 그런 면에서 HBase 가 오히려 프로그램과의 연동이 좋음.
* non-java 지원
HBase : jython, ruby, grooby script, REST, Thrift
Hive : Trhift, SerDe
CloudBase : jython
CloudBase 가 ANSI SQL 지원으로 프로그래밍 쪽은 가장 적합하나, jython 말고는 non-java 에 대한 지원이 없다. Hive는 jython 외에 Thrift 를 지원하지만, Thrift 방식으로 작업 할 경우, Native java 로 포팅하는 수준의 작업량이 발생 하리라 예상 됨.
* 결론
범용 DB라기 보다는, 일별로 발생하는 검색 로그나 아파치 로그 등과 같이 대용량 텍스트 파일에 대하여, 별도의 mapreduce 프로그램을 만들지 않고도, SQL 질의 만으로 hdfs 상에서 mapreduce 방식으로 원하는 결과를 가져올 수 있는 점이 장점이라 보임. 하지만 insert, 혹은 db load의 방식이 결국은 데이터를 hdfs 상에 업로드를 해야 하는 구조이기 때문에, 기존의 어플리케이션의 DB 커넥션 부분의 변경이 불가피 하고, non-java에 대한 지원, 특히 C/C++ 과의 연동이 편하지 않음.
insert 시 hdfs 상의 파일을 DB에 넣는 작업이 필요하고, select시 mapreduce 과정이 일어나므로 실시간 서비스에는 적합하지 않음. 대용량의 batch 작업에 적합.
* reference :
1. Thrift – http://incubator.apache.org/thrift
2. REST – http://en.wikipedia.org/wiki/REST
3. hive tutorial 동영상 – http://www.cloudera.com/hadoop-training-hive-tutorial
나라살림 잘해달라 맡겨놨더니 오년동안 뭘했는지 몰라라
세계화다 민주주의다 부르짖더니 벌거벗은 임금님 꼴 되었네
저기 저 아이가 웃는다 임금님이 벌거벗었다
성수대교 삼풍백화점 내려앉아도 아직 우리의 희망은 푸르렀다
열심히 일하는 자 살만한 나라 우리나라 대한민국인줄 알았다
나도 모르게 일은 벌어지고 내 희망도 날아갔네
차라리 꿈이라면 꿈이라면 좋겠네
I.M.F라는 생소한 말이 이 잘난 나랄 우습게 만들었네
하루 아침에 국제거지 취급받더니만 나 몰라라 정권만 싹 바뀌었네
이게 무슨 동네 축구요 골키퍼만 바뀌어 버렸네
북쪽에선 쌀 동냥에 아우성이요
남쪽에선 딸라달라 달라 달라달라달라
금 모아라 은 모아라 호들갑 떨더니 냄비같이 빨리 끓고 식겠네
없는 놈만 나누라네 이 고통을 분담하라네
차라리 꿈이라면 꿈이라면 좋겠네
권력 눈치 살살 보는 재벌나리들
정리해고 당할 자는 바로 나리나리나리나리
줄서기에 정신없는 의원나리들 여기 전두환식 고스톱 한 판 어때요
잘 들 논다 잘 들 논다 누굴 믿고 살아야 하나
일자리를 잃어버린 실업자 신세 멍하니 하늘만 바라보다
저 하늘은 평화롭고 볼만하구나 우리의 남은 희망도 푸르렀으면
숨이 차다 숨이 차다 내 가슴이 터질 것 같다
차라리 꿈이라면 꿈이라면 좋겠네
차라리 꿈이라면 꿈이라면 좋겠네
차라리 꿈이라면 빨리 깨어나고 싶다
//06.mp3
10년이 지났건만, 어째 지금 상황은 10년전 그 당시 보다 더 한것 같다.
아이에게 ‘정직함을 가르치는’ 냉철한 14가지 말
1. 네 눈으로 직접 확인해 보렴.
2. 같은 입장이었다면 기분이 어땠겠니?
3. 사람마다 생각이 다르단다.
4. 속여서 이기는 것보다 지는 게 낫단다.
5. 규칙은 반드시 지켜야 해
6. 남의 외모에 대해 함부로 말하면 안 된단다
7. 잘못을 했으면 바로 사과하자
8. 거짓말로 위기를 모면하면 마음이 슬퍼져
9. 엄마(나)라면 어떻게 했을까?
10. 남의 이야기에 귀 기울이자
11. 최선을 다하는 사람을 칭찬하자
12. ‘나만 좋으면 돼’ 하는 사람에겐 아무도 도움을 주지 않는단다.
13. 그러면 네 행동은 옳았니?
14. 말은 사람에게 상처를 주기 위해 있는 게 아니란다.
아이에게 ‘용기를 길러 주는’ 14가지 말
1. 어디 한번 해 볼까?
2. 이런 일도 할 수 있구나!
3. 마지막 결정은 스스로 하렴!
4. 실패했으면 다시 하면 돼
5. 무슨 일이든 최선을 다하자
6. 엄마(아빠)는 언제나 네 편이란다
7. 싸우지 않으면 안 될 때도 있단다.
8. 모든 것이 호박이라고 생각해 보렴!
9. 무서울 때는 큰 소리를 내 보자
10. 모르는 것을 물어보는 것도 용기란다
11. 남의 비웃음에 신경 쓰지 말아라.
12. 넌 훌륭한 사람이야
13. 부드러운 네가 참 좋아
14. 웃으면서 이야기할 때가 올 거야
아이의 ‘기분을 밝게 하는’ 14가지 말
1. 정말 잘 어울려
2. 좋은 일 있었니?
3. 엄마(아빠)는 언제나 널 믿는단다.
4. 웃는 얼굴이 최고야
5. 잘했어!
6. 엄마(아빠)도 네 나이 때로 돌아가고 싶구나.
7. ‘안녕’, ‘잘 자’ 하고 인사를 나누자
8. 참 좋은 친구들을 두었구나.
9. 이번엔 엄마(아빠)가 졌어
10. 우리, 조금 느긋해지자
11. 재미있니?
12. 자, 이제 싫은 소리는 이쯤에서 그만 하자
13. 이것이 네 장점이구나.
14. 어른이 다 되었네.
아이에게 ‘자신감을 심어 주는’ 14가지 말
1. 도와줘서 고마워
2. 참 즐거워 보이는구나.
3. 잘되지 않을 수도 있어. 누구에게나 그런 경우가 있단다.
4. 아무리 생각해도 이해할 수 없는 일이 있단다.
5. 하고 싶은 말은 확실하게 하렴
6. 참 재미있는 생각이구나!
7. 한번 해 보자
8. 잘 참았어. 훌륭하다
9. 엄마(아빠)는 네가 반드시 할 수 있다고 생각해
10. 어떤 경우에도 너는 너야
11. 엄마 아빠는 여기까지밖에 못했단다.
12. 가슴을 활짝 펴 보자
13. 남과 다르다는 건 매우 중요한 거야
14. 할 수 있다고 마음먹었으면 무엇이든 해 보자
아이가 ‘목표를 갖게 하는’ 14가지 말
1. 포기하면 모든 것이 끝이란다.
2. 초조해하지 마
3. 잘했어. 내일도 해 보자
4. 할 수 있는 계획을 세우자
5. 익숙해지면 다 잘될 거야
6. 흥미 있다면 시작해 보자
7. 끝까지 마무리하니 좋구나.
8. 관심을 가진다는 것은 매우 중요하단다.
9. 어렵겠지만 한번 해 볼까?
10. 널 다시 봤어!
11. 엄마(아빠)에게도 꿈이 있단다.
12. 엄마(아빠)도 처음엔 서툴렀어.
13. 잘되고 있니?
14. 고달팠던 경험이 언젠가는 도움이 된단다.
아이에게 ‘안정감을 주는’ 14가지 말
1. 내일도 좋은 일이 있을 거야
2. 네 나름대로의 방법이 좋은 거야
3. 세상에 쓸모없는 일은 없단다.
4. 괜찮아!
5. 뭐든지 다 잘하는 사람은 없어
6. 맞서 보면 어떻게든 해결된단다.
7. 네 자신을 믿으렴.
8. 처음부터 자신 있는 사람은 없단다.
9. 순수한 사람일수록 상처를 잘 받는단다.
10. 내일은 내일의 태양이 뜬단다.
11. 너는 소중해
12. 힘들면 도와줄게
13. 잘못은 누구에게나 있어
14. 좋은 것만 생각하자
아이를 ‘활발하게 하는’ 14가지 말
1. 크게 심호흡을 해 보자
2. 배가 고프면 일단 먹자
3. 넌 결코 약하지 않아
4. 밖에 나가 뛰어 놀으렴.
5. 우리 함께 노래할까?
6. 세상은 매우 넓단다.
7. 창문을 활짝 열어 놓으렴.
8. 네게 맡길게
9. 함께 걷자
10. 오늘은 날씨가 참 좋구나!
11. 아이들의 일은 노는 것
12. 너는 리더야
13. 굉장히 튼튼해졌구나.
14. 아빠랑 씨름할래?
아이에게 ‘감사와 감동을 가르쳐 주는’ 14가지 말
1. 네 안에 보물이 있어
2. 귀를 기울여 보렴.
3. 보렴.
4. 참 신기하구나.
5. 예쁜 것을 보니 마음이 좋구나.
6. 그림이나 음악을 통해 세상을 배울 수 있단다.
7. 참 행복하구나.
8. 학교에 갈 수 없는 아이도 많단다.
9. 잘 먹겠습니다, 잘 먹었습니다.
10. 참 맛있겠다.
11. 고맙습니다.
12. 음식을 남기지 않을 때 엄마는 정말 기쁘단다.
13. 살아 있어서 좋구나.
14. 네가 착해서 좋아.
——————————————————
동호회 게시판에 올라온 글인데, 보다 보니 꼭 아이에게만 해 줄 말은 아닌것 같다.
웹에서 수집한 데이터에서 전화번호를 키 값으로 음식점명을 추출했을 때 아래와 같은 결과가 나왔다.
사람 이 봤을 때 1번 문서 “메이필드호텔 봉래정” 과 2번 문서 “봉래정(메이필드호텔)”은 분명 다른 스트링이지만 같은 음식점을 지칭한다. 하지만 3번 문서 “카페 라리” 는 앞의 두개와는 전혀 다른 정보이다. 어떤 부류가 해당 전화 번호의 음식점인지는 직접 전화를 걸어보면 알겠지만, 그 사실 여부는 차치하고라도, 사람은 이 데이터 만으로 한 전화 번호에 두 개의 식당이 존재한다는 것을 판단을 할 수 있다.
이러한 것을 기계적으로 어떻게 판단 할까? 간단히 생각하면 각 스트링을 띄어쓰기 단위로 키워드를 추출하여 해당 키워드가 포함되어 있는 스트링을 추출해 내는 작업을 모든 키워드에 대하여 작업을 하면 될 것이다. 하지만, 이런 경우는 어떻게 하나..
키워드 “가네”가 3번 문서 “신가네 김밥”에도 포함되어 있으므로 같은 음식점으로 오판을 하고 만다. 이 외에도 여러 예외 사항이 있을 것이다. 인공지능을 공부한 사람답게 좀 더 인공지능적으로 해결을 해 보자. 이 경우는 여러 데이터들을 어떻게 분류(classification) 또는 군집(clustering) 하는가 중, clustering에 해당 한다고 볼 수 있다. 신경망, svm 등의 학습 기반 방법을 쓸 수도 있겠지만, 대량의 학습 데이터를 만드는 것도 일이 거니와, 데이터의 형태가 너무도 다양하다. 여기서는 그렇게 복잡한 방법 말고 단순히 IR에서 문서의 유사도를 계산하는데 사용되는 코사인 유사도 계산등의 방법으로도 효과가 상당할 것 같다. 하지만 이것을 현재 문제에 적용하기에는 좀 부족하다. key 02-123-4567을 가지고 좀 더 단순화 해 보자.
각 문서의 스트링에서 단어를 추출하면 “메이필드호텔”, “봉래정”, “카페”, “라리” 총 네 개의 단어를 뽑을 수가 있다. 형태소 분석기를 사용하게 되면 “메이필드”, “호텔” 로 더 쪼개서 총 다섯개의 단어를 뽑을 수도 있겠지만, 여기서는 문제 해결을 위한 과정을 단순화 하기 위해 “메이필드호텔”, “봉래정”, “카페”, “라리” 네개의 단어를 사용하자. 이렇게 뽑은 키워드를 비트로 표현하면 각 문서는 아래와 같은 벡터로 표현 될 수 있다.
모든 벡터가 0, 1 로 표현되는 이진 벡터의 경우는 해밍 거리(hamming distance) 를 적용할 수 있다. 해밍 거리는 서로 다른 비트의 개수를 센다. 예를 들어 (1, 0, 1, 0), (0, 0, 1, 1) 일 때 거리는 2 이다. 가질 수 있는 거리의 최대값을 distancemax 라 할 때, 문서 a, b 에 대한 유사도 similaritya,b 는 아래와 같이 구할 수 있다.
이를 이용해서 유사도를 계산해 보면 아래와 같다.
음… 이래서는 곤란하다. 관계 없는 (1, 3), (2, 3) 이 유사도가 2로 높게 나온다. 단순히 벡터간의 거리만을 판단하기 때문에 이런 결과가 나온다.(예를 잘못 들었다) 실제 문서상에서 해당 단어가 존재하는지 여부가 중요한데 이 부분이 고려 되지 않았다.
다시 코사인 유사도를 생각을 해 보자. 문서 a 가 wa1, wa2, wa3… 의 키워드를 가지고 있고, 문서 b 가 wb1, wb2, wb3의 키워드를 가지고 있을 때, a 는 벡터 (wa1, wa2, wa3…), b 는 벡터 (wb1, wb2, wb3…) 로 나타낼 수 있다. 이 때, 문서 a b 간의 코사인 유사도는 아래와 같은 공식으로 계산 할 수 있다.
이를 풀어 쓰면 아래와 같다.

이를 위에서 변환한 이진 벡터로 적용을 해 보면 a.b 의 내적은 결국 둘다 1인 비트의 갯수가 되고, 각 벡터의 길이는 1인 비트의 갯수와 대략 비슷하게 된다. 이것을 a, b 둘다 있는 경우, a엔 있지만 b에 없는 경우, 반대로 b엔 있지만 a에는 없는 경우 등을 고려 한다. 그러면 유사도 계산식은 아래와 같이 간략화 할 수 있다.

여기서 n11은 문서 a, b 모두 1인 비트 수, n10은 문서 a 만 1인 비트 수, n01은 문서 b 만 1인 비트 수 이다.
이 식을 가지고 key 02-123-4567 의 문서들의 유사도를 계산 해 보자.

즉, 문서 1,2 는 유사도가 1이고 1,3 2,3 은 유사도가 0이다. 유사도 계산값이 0보다 큰 것만 골라 내면 될 것이다. 그러면 1, 2 두개의 문서가 묶인 부류 하나와 3 혼자 있는 부류 하나 해서 두개의 부류를 얻게 된다.
좀 더 많은 문서와 단어를 가지고 더 살펴 보자.

유사도가 0보다 큰 것들만 뽑으면 (1,2), (1,3), (2,6), (4,5) 이다. 이를 문서번호로 이진트리로 그려보자.
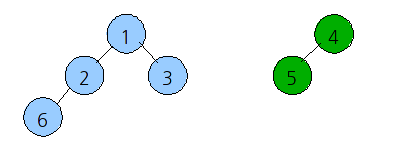
이렇게 두개로 구분을 할 수가 있게 된다.
이러한 작업이 가능하기 위한 선행 작업으로 먼저 각 단어를 잘 뽑아 낼 수가 있어야 하고, 이를 위해서는 형태소 분석이나 단어 사전을 잘 구축을 해야 한다. 현재 상황에서는 음식점명들이 대부분 명사이기 때문에 전체 음식명들을 가지고 띄어쓰기 단위나, (, ), [, ], – 등을 구분자로 사용하여 키워드만 추출을 잘 해도 단어 사전을 기계적으로 쉽게 구축 할 수가 있다.
이 아이디어를 바탕으로 이제 실제 구현만 하면 되겠다. 검색의 품질을 높이는데 있어서 색인기, 쿼리 분석기 등의 엔진단도 중요하지만, 색인 데이터를 얼마나 잘 정제해서 엔진에 넣느냐는 데이터 마이닝도 무척 중요하다고 생각한다. 구현을 마치고 서비스에 적용을 했을 때, 맛집 검색의 그룹핑 정확도가 좀 더 높아질것이라 기대한다.
reference :
1. 코사인 유사도 cosine similarity http://en.wikipedia.org/wiki/Cosine_similarity
2. 내적 http://ko.wikipedia.org/wiki/%EB%82%B4%EC%A0%81
2-1. inner product http://en.wikipedia.org/wiki/Inner_product
3. 해밍 거리 http://ko.wikipedia.org/wiki/%ED%95%B4%EB%B0%8D_%EA%B1%B0%EB%A6%AC
3-1. hamming distance http://en.wikipedia.org/wiki/Hamming_distance
요 근래들어 나라가 더욱 더 어수선 하다. 용산 참사에 이어 연쇄 살인범 강호순 검거까지… 그 와중에 금융연구원장이 현 정부와 견해가 달라 사의를 표명했다는 기사가 있더라. 찌질한 소리나 해대는 조선일보 기사가 상위에 랭크되어 검색되더라만은 그거 말고 그 간의 일을 간략히 정리한 이데일리 기사를 링크한다.
http://www.edaily.co.kr/news/newsread.asp?strPage=1&searchDate=20090128&sub_cd=D0&newsid=02358326589562312&DirCode=0010102&MLvl=1&curtype=read
이 분이 금융연구원 홈페이지에 남긴 글이 와닿는게 있어서 전문을 남긴다. 금융연구원장이라는 기관의 최고 윗 사람으로써, 어떠한 마음가짐으로 그 자리를 맡아 왔는지를 알 수 있다. 며칠전 용산에서 국민이 여섯이나 죽었는데도 엊그제 TV 토론회에 나와서 유감의 말 한마디 하지 않은 우리 대통령과 어찌나 비교가 되는지… 아, 우리 대통령이 아니구나… 이명박은 소수의 잘사는 사람들을 위한 대통령이지, 대다수의 국민을 위한 대통령은 아니지, 참.
윗 자리에 앉은 사람으로써 올바른 소신을 가지고 그 소신을 지키려 애쓰는 모습에서 존경의 마음이 절로 든다. 이런 분들이 자기 자리에서 꿋꿋하게 자기 역할을 충실히 해 주셔야 할텐데, 이명박 대통령은 기가차서 말도 안나오는 경찰청장 같은 사람들만 자꾸 자꾸 옆에 두니, 다른 한편으로는 걱정이 되지 않을 수가 없구나.
원문은 한국금융연구원 홈페이지 http://www.kif.re.kr 의 ‘공지사항’ 링크의 ‘일반공지’ 게시판의 http://www.kif.re.kr/KIF/Bbs/Detail.aspx?NodeID=267&BbsID=1667 에서 볼 수 있다.
1년 반 전, 제가 원장에 취임하면서 여러분께 말씀드렸습니다. 금융연구원을 국제적으로 인정받을 수
있는 연구기관으로 한 단계 더 발전시키자고. 금융연구원의 발전은 국내 금융정책의 수준을 높이고 우리 금융산업을 발전시키는
일이라고. 그러나 이 일은 제가 원장으로서 혼자 할 수 있는 일은 아니었습니다. 우리 모두가 함께 노력해야 하는 일이었습니다.
연구는 여러분의 몫입니다. 원장의 몫은 여러분들이 소신껏 오직 여러분의 학자적 양심과 신념에 따라 연구할 수 있도록 도와드리는
일입니다. 때로는 외풍을 막아주고, 때로는 여러분을 대신해서 외부의 부당한 압력에 대항해 싸우는 일입니다. 때로는 여러분의 입이
되고, 때로는 여러분의 손과 발이 되는 일입니다. 그것은 연구의 자율성과 독립성을 지키는 일입니다.
저는 지난 1년
반 원장으로서의 제 몫의 일을 최선을 다해 성실하게 그리고 열심히 했습니다. 그리고 제 임기를 절반 밖에 채우지 못하고 오늘
여러분 곁을 떠나게 되었습니다. 이제 여러분을 더 이상 지켜드리지 못하는 미안한 마음을 안고 여러분 곁을 떠나게 되었습니다.
연구의 자율성과 독립성을 한갓 쓸데없는 사치품 정도로 생각하는 왜곡된 ‘실용’ 정신, 그러한 거대한 공권력 앞에서 이제는 제가
더 이상 여러분에게 도움이 되기보다는 짐이 되어 가고 있다는 생각에 금융연구원을 떠나기로 결정하였습니다.
연구원을
정부의 Think Tank(두뇌)가 아니라 Mouth Tank(입) 정도로 생각하는 현 정부에게 연구의 자율성과 독립성은 한갓
사치품일 수밖에 없습니다. 정책실패의 원인을 정책의 오류에서 찾기보다는 홍보와 IR에서 찾는 현 정부의 상황 판단 앞에서, 잘된
것은 모두 내 탓이요 잘못된 것은 모두 네 탓이라고 보는 현 정부의 인식 앞에서, 결정은 내가 할테니 너희들은 그저 일사불란하게
따라오기만 하라는 현 정부의 일방통행식 밀어붙이기 사고방식 앞에서 정부 정책에 대한 비판은 비판의 잘 잘못을 따질 필요도 없이
현 정부의 갈 길을 가로막는 걸림돌에 불과할 것입니다. 아니, 비판이 아니더라도 정부의 정책을 앞장서서 적극적으로 홍보하지 않는
연구원이나 연구원장은 현 정부의 입장에서는 아마 제거되어야 할 존재인 것 같습니다. 경제성장률 예측치마저도 정치 변수화한 이
마당에 그것은 아마 당연한 일이겠지요.
돌이켜 보면 정부의 정책이 지금처럼 이념화된 적도 흔치는 않았던 것
같습니다. 정책의 논의 과정이 생략되고 사고와 아이디어의 다양성이 이처럼 철저히 무시된 적도, 아니 봉쇄된 적도 흔치는 않았던
것 같습니다. 적어도 우리 사회가 민주화된 이후에는 말입니다. 경제적 논리와 경험적 증거보다는 주의와 주장만 난무하는 무리한
정책, 네 편과 내 편을 가르는 정책, 모든 국민에게 골고루 혜택이 돌아가기보다는 특정 집단에게 혜택이 집중되는 정책, 그
앞에서 사고와 아이디어의 다양성이 인정될 수가 없겠지요. 이에 근거한 활발한 정책 토론 또한 불편하겠지요.
여러
가지 사례를 들 필요도 없습니다. 현 정부가 금과옥조처럼 여기는 금산분리 완화정책을 살펴봅시다. 재벌에게 은행을 주는 법률
개정안을 어떻게 ‘경제살리기 법’이라고 부를 수 있습니까. 어떻게 ‘개혁입법’이라고 부를 수 있습니까. 그것을 어떻게 국제적
조류라고 감히 주장할 수가 있습니까. 어떻게 우리나라가 전세계에 유래가 없을 정도로 금산분리가 가장 철저한 나라라고 주장할 수
있습니까. 정부의 주장과는 달리, 그리고 일부 보수집단 금융이론가들의 주장과는 달리 우리나라는 전세계 선진국에는 유래가 없을
정도로 산업자본의 금융지배가 가장 많이 허용된 나라입니다. 그 폐해도 가장 많이 경험한 나라입니다.
여러분들은
외국의 경우 은행이든 증권사든 보험회사든 산업자본의 지배 아래 있는 세계적 금융기관을 보신 적이 있습니까. 제가 과문해서 그런지
모르겠습니다만 저는 아직 산업자본의 지배 아래 있는 세계적 은행, 세계적 증권사, 세계적 보험사의 예를 듣지도 보지도
못했습니다. 그러나 우리나라의 경우에는 은행을 제외하면 증권, 보험 등 제2금융권의 주요회사들은 거의 대부분 산업자본 즉,
재벌의 지배 아래 있습니다. 이래도 저희 나라가 전세계에서 금융과 산업이 가장 철저히 분리된 나라라고 할 수 있겠습니까. 그리고
불행히도 재벌의 지배 아래 있는 우리나라의 증권사, 보험사들은 비록 국내시장에서는 1류 행세를 하지만 국제시장에서는 2류, 3류
수준에 불과한 실정입니다. 재벌의 소유를 금지했기 때문에 우리나라 증권사, 보험사가 세계시장에서 2류, 3류에 머물러 있는 것이
아닙니다. 이래도 재벌의 은행소유를 금지하고 있기 때문에 우리나라의 금융산업이 국제적인 수준으로 발전하지 못한다고 할 수
있습니까. 그렇게 주장하기 전에 우선 재벌들은 자기들이 소유한 증권사, 보험사를 국제경쟁력을 갖춘 글로벌 금융사로 만들어야
합니다. 그런 능력이 있다는 것을 보여야 합니다. 그렇지 않다면 은행을 재벌에 주어야 한다는 주장은 마치 프리메라 리그의 꼴찌
축구팀에게 야구를 하도록 해주면 월드시리즈 챔피언이 될 거라는 주장과 다르지 않습니다. 복잡하고 어려운 경제이론을 내세우기도
전에 이런 평범한 상식적 결론을 현 정부는 왜 진솔하게 인정하지 않는지 이해할 수 없습니다. 저희 연구원으로서는, 그리고 저
개인으로서도 — 원장으로서 뿐만 아니라 금융학자로서 — 정부의 금산분리 완화정책을 합리화할 수 있는 논거를 도저히 만들
재간이 없습니다. 정부의 적지 않은 압력과 요청에도 불구하고 말입니다.
재벌의 은행소유를 허용하는 은행법과
금융지주회사법 등 개정안은 금융분야에서의 대운하 정책과 다르지 않습니다. 한번 국토를 파헤치고 나면 파괴된 환경을 되돌릴 수
없듯이 일단 은행이 재벌의 사금고가 되면 이를 되돌릴 수가 없습니다. 환경파괴의 영향이 모든 국민에게 미치는
외부불경제성(external diseconomies)과 마찬가지로 은행의 사금고화도 금융체제 위험(systemic risk)을
높이는 외부불경제성을 갖고 있습니다. 일단 파괴된 환경은 사후 감독이나 제재로 쉽게 복구되지 않듯이 은행 사금고화의 폐해도 현
정부와 일부 보수 금융학자들의 주장과는 달리 사후 감독이나 제제를 강화한다고 쉽게 방지되거나 시정될 수 있는 것이 아닙니다.
그럼에도 불구하고 대운하 정책이나 금산분리 완화정책이 쉽게 포기되지 않는 이유는 아마도 그 혜택이 특정 집단에 집중되기 때문인
것 같습니다. 특정집단의 이익이 상식을 압도하는 상황이 벌어지고 있다고 밖에 달리 결론지을 수 없는 것 같습니다. 저는 잘
모르겠습니다만 4대강 정비사업이라는 명분으로 삽질을 하다가 나중에 슬쩍 연결하면 대운하가 된다고들 합니다. 재벌의 은행소유한도를
4%에서 10%로 올려 일단 발을 들여놓고 나서 나중에 슬쩍 조금만 더 풀어주면 되니까 이것도 닮은꼴입니다.
글로벌
금융위기를 우리의 경제위기로 키우고 있는 정부의 거듭된 오판과 실정이 또 다른 사례가 되겠지요. 전국민이 합심해서 글로벌
금융위기에 총력 대응해도 부족할 때입니다. 다양한 의견이 표출되고 진지한 논의를 거쳐 국민의 의지가 정책으로 결집되어야 할
때입니다. 정부는 허심탄회하게 귀를 열어야 할 때입니다. 그러나 좌-우, 진보-보수, 네 편-내 편, 네 탓-내 탓 가르기에
집착하다 보니 정부의 관심은 다른 데 있는 것 같아 보입니다. 정부는 다양한 의견의 자유로운 표출과 논의를 막고 싶은 것
같습니다. 위기상황에 대한 판단마저도 정책적으로 왜곡되고 수시로 번복되는 것 같습니다. 그래서 정책대응에도 실기를 하는 것
같습니다. 서로 상충되는 정책이 남발되는 것 같습니다. 위기는 점점 더 현실로 다가오는 것 같습니다. 그러니 국민들은 점점 더
어려워지고 정부에 대한 국민의 불신도 커지는 것 같습니다.
이럴 때일수록 연구원의 역할이 중요합니다. 연구의
자율성과 독립성이 그 어느 때보다 중요합니다. 이럴 때 연구원 동료 여러분의 곁을 떠나는 제 심정도 착잡하기 그지없습니다.
그러나 ‘법에 규정’된 원장의 임기를 부정하는 ‘법치’ 정부의 이중 잣대(double standard) 앞에서 연구의 자율성과
독립성을 보장해달라고 한들 무슨 소용이 있겠습니까. 연구의 자율성과 독립성을 위해 원장의 임기가 보장되어야 한다고 한들 무슨
소용이 있겠습니까. 그리고 연구의 자율성과 독립성을 희생하는 대가로 연구원의 원장직을 더 연명한다면 그것이 무슨 의미가
있겠습니까. 원장의 직은 제 개인의 영달을 위해 있는 것이 아니라 연구원의 발전을 위해 있는 것이기 때문입니다.
근래
돌아가는 세태를 보면서 제 후임으로 어떤 분이 오실까 궁금해지기도 합니다. 여러분들도 마찬가지겠지요. 어떤 분이 원장으로 오시든
여러분께서는 동요하지 마시고 조용히 연구에 매진해 주시기를 부탁드립니다. 제가 여러분께 누누이 말씀드렸듯이 연구원을 이끌어
나가는 것은 원장이 아니라 여러분 자신이라는 점을 한시도 잊지 마시기 바랍니다. 제가 원장으로 재임했던 기간 중에도 연구원을
이끌어 왔던 것은 제가 아니고 여러분이었습니다. 저는 단지 여러분을 도와드리는 역할만을 하였을 뿐입니다.
눈앞의
이익에 눈이 멀어 정부의 요구에 맹목적으로 따라서는 안됩니다. 금융연구원의 품격을 유지해야 합니다. 금융연구원에 대한 외부의
신망과 신뢰를 유지해야 합니다. 긴 세월을 두고 보면 그래야만 우리 금융연구원이 한 단계 더 발전할 수 있습니다. 그것이 우리가
국가와 국민에 보답하는 길입니다.
한동안 쉽지 않은 시절이 금융연구원에도 올 것입니다. 그러나 어느 시인이
말했습니다. 이 세상에 흔들리지 않고 피는 꽃은 없다고. 이 세상에 젖지 않고 피는 꽃은 없다고. 여러분이 겪는 어려움이
금융연구원의 꽃을 피우는 자양분이 될 것이라고 믿어 의심치 않습니다.
저는 비록 금융연구원을 떠나기는 하지만 동료
여러분을 아주 떠나는 것은 아닙니다. 뜻을 같이 하는 학자들이 한 평생을 같이 하듯 저는 여러분과 평생을 같이 할 것입니다.
여러분의 동료로서 또한 선배로서 저는 금융연구원을 떠나서도 금융연구원의 발전을 위해 여러분과 같이 노력할 것입니다. 금융연구원을
금융연구자들의 품으로 되찾을 때까지…..
2009년 1월 31일
한국금융연구원 원장 이동걸
http://www.freeegg.com/flash/player/channelPlayer.swf?id=176288&skinNum=1&channelID=miioel
고등학생들에게 하는 강의인 듯 하다. 함 보시길… 한 일이분 광고가 나온 후 본 영상이 나온다.
내 개인 문제만으로도 충분히 시끄러우니, 나라가 거꾸로 가건 말건 신경안쓰고 싶지만서도 우리 대통령님땜에 하루도 조용한 날이 없구나. 회사 문제로 아주 머리가 아픈 상황인지라 왠만해선 머리 아픈 일은 신경 안쓰려고 하지만 뉴스는 챙겨 보는 편이다. 하지만, 요즘 뉴스 보면 욕나올 때가 한두번이 아니라서, 회사 문제가 정리 될때까지 만이라도 뉴스를 잠시 끊어야 할까 보다.
